검색결과 리스트
전체에 해당되는 글 153건
- 2008.08.04 Java Pitfalls: Excuting an external program using Runtime.exec() method or ProcessBuilder class
- 2008.07.30 eclipse +cvs 사용하기
- 2008.07.30 Eclipse +tomcat 플러그인
- 2008.07.22 ms-sql 쿼리 관련 공부.
- 2008.07.22 테이블 정보 보기 , 테이블 필드값 보기
- 2008.07.21 ms-sql 서브커리 속도 올리기
- 2008.07.19 탐켓 아파치 jk 커넥션 연결 ~!!
- 2008.07.01 vmware 외부 아이피일경우 net8 로 설정 방법
- 2008.06.19 sort() 하는 방법
- 2008.06.02 vi 에디트 명령어
글
Java 프로그램에서 외부 프로그램을 실행하고 싶을 때, Runtime.exec() 또는 Java 1.5에서 추가된 ProcessBuilder를 사용해 Process 객체를 얻을 수 있다. 처음으로 이런 프로그램을 짤 때, 실수한 것이 없어보이는데도 실행한 프로그램이 종료되지 않는 경우가 있다. 더군다가 어떤 경우엔 정상적으로 종료되고 어떤 경우엔 종료가 되지않는 경우도 보인다.
원인은 바로 Process 클래스의 API Reference에 있는 다음과 같은 설명에서 찾을 수 있다.
The created subprocess does not have its own terminal or console. All its standard io (i.e. stdin, stdout, stderr) operations will be redirected to the parent process through three streams (getOutputStream(), getInputStream(), getErrorStream()). The parent process uses these streams to feed input to and get output from the subprocess. Because some native platforms only provide limited buffer size for standard input and output streams, failure to promptly write the input stream or read the output stream of the subprocess may cause the subprocess to block, and even deadlock.
즉, Java에서는 Child 프로세스로의 표준 입출력을 Parent 프로세스가 다루어주어야 한다. 당연하게도, Child의 출력을 언제까지고 버퍼링할 수 없기 때문에, 다른 프로그램을 실행할 때는, 특히 표준 입출력이 존재하는 프로그램을 실행할 경우에는, 항상 이 스트림들의 입력 또는 출력을 제대로 다루어주어야 한다.
이러한 동작은 일반적으로 프로그래머들이 익숙한 시스템콜들, 이를테면 UNIX 계열의 fork()/exec()나 Windows의 CreateProcess()처럼, parent 프로세스의 터미널/콘솔을 공유하는 동작과는 다르기 때문에, 프로그래머들이 쉽게 간과하고 실수하기 쉽다. 더군다나 API Reference가 이러한 점을 명확히 설명하고 있지도 않다.
해결책은 당연하게도 표준 입력이 필요할 때는 Process.getOutputStream()을 이용하여 필요한 입력을 해주고 스트림을 닫아주어야하고, 표준 출력이 필요할 때는 Process.getInputStream() 그리고 Process.getErrorStream()을 이용하여 스트림을 비워주어야한다. 드물겠지만 만약 실행할 프로그램이 interactive한 프로그램일 경우에는 입출력에 좀 더 신경을 써야한다.
다음은 표준 출력을 비워주기 위한 코드가 들어간 간단한 예다.
- Runtime rt = Runtime.getRuntime();
- try {
- Process proc = rt.exec("cmd /c dir");
- // Process proc = new ProcessBuilder().command("cmd", "/c", "dir").start();
- InputStream is = proc.getInputStream();
- BufferedReader reader = new BufferedReader(new InputStreamReader(is));
- String line;
- while ((line = reader.readLine()) != null) {
- System.out.println(line);
- }
- int exitVal = proc.waitFor();
- System.out.println("Process exited with " + exitVal);
- } catch (Exception e) {
- System.err.println("Failed to execute: " + e.getMessage());
- }
Runtime rt = Runtime.getRuntime();
try {
Process proc = rt.exec("cmd /c dir");
// Process proc = new ProcessBuilder().command("cmd", "/c", "dir").start();
InputStream is = proc.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(is));
String line;
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
int exitVal = proc.waitFor();
System.out.println("Process exited with " + exitVal);
} catch (Exception e) {
System.err.println("Failed to execute: " + e.getMessage());
}
표준 출력 뿐만 아니라 표준 에러까지도 처리를 할 수 있어야 좀 더 일반적인 코드일 것이다. 표준 에러의 버퍼가 차버리면 표준 출력을 비우려고 해도 블럭될 수 있다. 이러한 문제는 Java World의 When Runtime.exec() won't 라는 글에서 StreamGobbler라는 클래스를 도입해서 약간 더 우아하게 해결하고 있다. 하지만, 간단한 작업을 하기 위해 쓰레드를 사용하고 있기 때문에 좀 오버킬이라는 생각이 든다.
표준 출력과 표준 에러를 간단하게 무시하고 다른 프로그램을 실행할 수 있도록 하는 옵션이 있다면 자주 사용할 수 있으며 편리할 듯 하다. 또는, 디폴트 동작을 일반적인 시스템콜의 동작과 비슷하게 만들어주는 것도 괜찮을 듯하다. 시간이 나면 이런 방식의 Wrapper를 찾아보거나 만들어보아야겠다
설정
트랙백
댓글
글
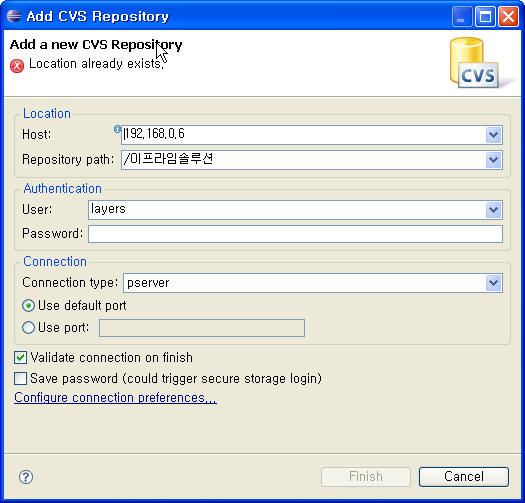
세팅
1. windows -> open perspective -other -> cvs repository Exploring 을 하여 cvs 퍼스펙티브를 연다.
2. cvs pepositories 에서 오른족 버튼 ->new ->pepository location 을 클릭하여
cvs 연결 마법사 엽니다.
3. 그림과 같이 세팅합니다.
설정
트랙백
댓글
글
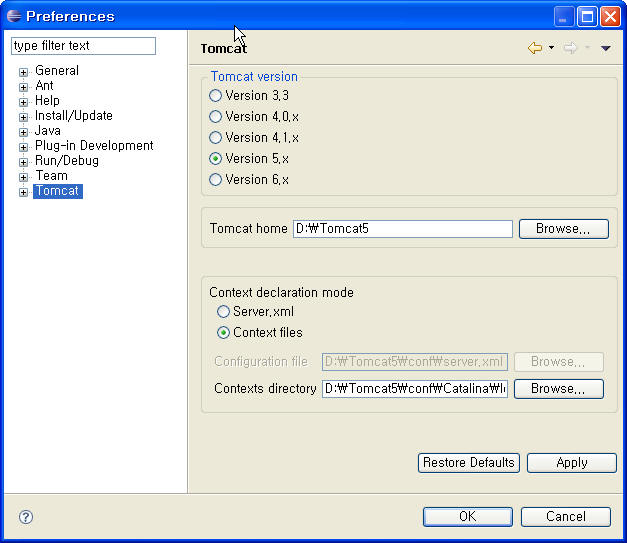
설정
트랙백
댓글
글
//http://sqler.pe.kr/web_board/view_list.asp?id=599&read=4382&pagec=23&gotopage=23&block=2&part=MyBoard7&tip=
//
안녕하십니까? 유일환(ryu1hwan@empal.com)입니다.
SQL Server의 실행계획과 인덱스에 대해 간단히 적어볼까 합니다.
먼저 인덱스가 무엇인지는 다들 아시리라 믿습니다.
물론, 실행계획이 무엇인지도요.
인덱스가 있는 테이블과 없는 테이블간에 성능 차이, 성능을 확인 하는 정도를 다루고 있습니다.
계속해서 어려운 부분도 다루도록 노력하겠습니다.
1. 먼저 할일은 인덱스 없는 테이블과 인덱스 있는 테이블을 생성하는 일입니다.
IF OBJECT_ID('TBL_NO_IDX') IS NOT NULL DROP TABLE TBL_NO_IDX
IF OBJECT_ID('TBL_IDX') IS NOT NULL DROP TABLE TBL_IDX
go
CREATE TABLE TBL_NO_IDX
( noInt int,
tmpTxt char(800))
go
INSERT INTO TBL_NO_IDX VALUES (1, 'A')
-- 만건의 데이터를 TBL_NO_IDX테이블에 입력
DECLARE @i as int
DECLARE @maxNo as int
SET @maxNo = 1
WHILE @maxNo < 10000
BEGIN
INSERT INTO TBL_NO_IDX
SELECT noInt + @maxNo, 'A'
FROM TBL_NO_IDX
WHERE noInt + @maxNo <= 10000
SELECT @maxNo = MAX(noInt)
FROM TBL_NO_IDX
END
go
SELECT COUNT(*)
FROM TBL_NO_IDX
go
------------------------------------------------------------------------------
TBL_NO_IDX 테이블에는 만건의 데이터가 만들어져 있습니다.
이 테이블을 CREATE할 때, tmpTxt라는 컬럼에 800을 주었으므로 한 레코드당
크기는 804바이트 정도가 될 것입니다. SQL Server는 한 페이지(*)에 8000바이트 정도의
데이터를 담을 수 있습니다. 그러므로 한 페이지에 10건 정도의 데이터가
들어가게 됩니다.
*페이지(page):SQL Server의 페이지 입출력을 위한 최소 단위로서 데이터를 읽거나 쓸때
페이지 단위로 동작하게 됩니다.
여기서 1000건의 데이터를 넣기 위해 사용한 방법을 보시면 WHILE문에 조건으로 @maxNo를
사용한 것을 볼 수 있습니다. 이 방법을 사용하게 되면, 10000건의 데이터를 금방 집어 넣을
수 있습니다.
WHILE 루프가 처음 돌때, 2건의 데이터가 들어가 있고, 2번째 돌 때는 4건의 데이터가 들어가고,
3번째 돌때는 8건의 데이터가 들어가고, 4번째는 16건, 이런식으로 2의 n승만큼의 데이터를 한번에
넣게 되므로 WHILE문을 만번 반복하지 않고, 데이터를 넣을 수 있게 됩니다. 이런 것이 집합처리(*)의
기본원리라 할 수 있습니다. 들어가 있는 집합들에 최대값을 더해서, 2배의 데이터를 만들어 내는
것입니다.
*집합처리 : 프로그래머들이 SQL문을 다룰때, 한 개의 레코드에 대해서만 생각을 하고 순차적으로
접근하는 경향이 있습니다. 하지만, SQL은 비 절차적이기 때문에, 이는 옳은 방법이 아닙니다.
우리 개발자들은 SQL을 다룰때, 집합적으로 데이터를 다루어야 합니다. 한번에 한 건의 데이터가 아닌
한번에 여러 집합을 다룰 수 있어야 합니다.
2.데이터를 모두 담았으므로 해당 테이블과 동일한 TBL_IDX라는 테이블을 만들어 내고, TBL_IDX
테이블에는 인덱스를 생성해 줍니다.
--인덱스 생성을 위한 테이블 생성
SELECT * INTO TBL_IDX
FROM TBL_NO_IDX
go
--인덱스 생성
CREATE UNIQUE INDEX tbl_idx_idx1 ON TBL_IDX(noInt)
go
--테이블의 크기 확인
SELECT id, used, rowcnt, name
FROM sysindexes
WHERE id IN (OBJECT_ID('TBL_NO_IDX'), OBJECT_ID('TBL_IDX'))
go
--1200정도의 페이지를 가지고 있다.
id used rowcnt name
1977058079 1251 10000 TBL_NO_IDX
1993058136 1139 10000 TBL_IDX
1993058136 25 10000 tbl_idx_idx1
위의 SQL문을 보면 SELECT INTO라는 것이 있는데, 이것은 FROM절에 기술한 테이블과 동일한
테이블을 쉽게 만들 수 있게 해줍니다. SELECT INTO는 여러가지로 응용이 가능하므로 나중에
따로 설명하도록 하겠습니다.
TBL_IDX에는 인덱스를 설정하고, TBL_NO_IDX에는 인덱스를 설정하지 않습니다.
CREATE UNIQUE INDEX로서 UNIQUE한 인덱스를 TBL_IDX에 설정합니다.
인덱스의 이름은 tbl_idx_idx1입니다.
준비된 테이블들의 크기를 보기 위해 sysindexes테이블을 SELECT합니다.
여기서 used라는 컬럼은 해당 object가 얼만큼의 페이지를 가지고 있는지를 보여줍니다.
1페이지는 8000바이트, 즉 8K이므로(정확히 8000바이트는 아닙니다.) 각 테이블이 8 * 1200KB정도의
크기를 가지고 있습니다. 그리고, tbl_idx_idx1에 대해서는 25페이지가 따로 설정되어 있는 것을 알
수 있습니다. 인덱스는 int컬럼인 noInt만 가지고 설정을 했으므로 실제 테이블보다 크기가 적을 수
밖에 없겠죠.
3. 실행계획을 보기 위해 설정을 합니다.
이 설정을 하기 전에, 그래픽으로 보는 실행계획은 OFF를 시키셔야 합니다.
--실행계획과, IO를 보기위한 설정을 ON
SET STATISTICS IO ON --페이지의 입출력 수를 알 수 있다.
SET STATISTICS PROFILE ON --실행계획에 대한 결과를 알 수 있다.
go
여기서 PROFILE ON은 실행계획을 보여주지만, 해당 실행계획이 실제 실행된 결과도 보여주게 됩니다.
나중에 보시면 아시겠지만, ROWS와 Executes를 보여줌으로써, 해당 과정에서 몇 Row가 발생되고,
해당 과정이 몇번 실행 됐는지를 알 수 있습니다.
4. 다음의 쿼리를 통해 인덱스를 사용한 경우와 사용하지 않은 경우의 상태를 비교 합니다.
SELECT *
FROM TBL_NO_IDX --인덱스가 없는 테이블
WHERE noInt = 3
SELECT *
FROM TBL_IDX --인덱스가 있는 테이블
WHERE noInt = 3
go
--인덱스가 없는 테이블의 실행계획 및 IO
Rows Executes StmtText
1 1 SELECT * FROM [TBL_NO_IDX] WHERE [noInt]=@1
1 1 |--Table Scan(OBJECT:([PLANDB].[dbo].[TBL_NO_IDX]), WHERE:([TBL_NO_IDX].[noInt]=Conv
'TBL_NO_IDX' 테이블. 스캔 수 1, 논리적 읽기 수 1250, 물리적 읽기 수 0, 미리 읽기 수 0.
--인덱스가 있는 테이블의 실행 계획 및 IO
Rows Executes StmtText
1 1 SELECT * FROM [TBL_IDX] WHERE [noInt]=@1
1 1 |--Bookmark Lookup(BOOKMARK:([Bmk1000]), OBJECT:([PLANDB].[dbo].[TBL_IDX]))
1 1 |--Index Seek(OBJECT:([PLANDB].[dbo].[TBL_IDX].[tbl_idx_idx1]), SEEK:([TBL_IDX].[
'TBL_IDX' 테이블. 스캔 수 1, 논리적 읽기 수 3, 물리적 읽기 수 0, 미리 읽기 수 0.
실행 한 결과를 보면, 결과 밑에 실행계획이 보여지고, 메세지 창을 확인하게 되면 페이지의 IO를
보여줍니다.
TBL_NO_IDX의 실행계획은 Table Scan이라는 연산을 하고 있습니다.
(실행계획을 보는 순서에 대해서는 나중에 따로 다루도록 하겠습니다.)
TBL_NO_IDX에는 WHERE절에 기술된 noInt = 3이라는 값을 찾을수 있는 인덱스가 없으므로 테이블 전체를
스캔한다는 것이 됩니다. 그 결과, 논리적 읽기 수는 실제 테이블의 크기인 1251페이지에 가깝다는
것을 알 수 있습니다. 여기서, 논리적 읽기 수는 실제 데이터를 위해 페이지를 읽은 수가 됩니다.
물리적 읽기 수는 메모리에 데이터 페이지가 없으므로 실제 물리적으로 저장된(하드같은곳.)곳에서
페이지를 읽어온 횟수가 됩니다.(여기서는 해당 페이지들이 모두 메모리에 올라와 있으므로 물리적
읽기 수가 없습니다.) 실제로, 똑같은 쿼리가 처음에는 느리고, 두번째 부터 빠른 이유는 이런
이유입니다. 처음 실행된 쿼리의 데이터는 물리적 읽기로 데이터를 찾아와야 하고, 두번째 같은 쿼리는
메모리에서 데이터를 찾아오기 때문이죠.
결과적으로 TBL_NO_IDX테이블에서 한건을 찾아오기 위해 1250페이지를 뒤진 것을 확인 할 수 있습니다.
반면에 TBL_IDX테이블에 대한 것을 살펴 보면, 실행계획은 TBL_NO_IDX과 틀린 것도 알 수 있고,
논리적 읽기 수 역시 3밖에 안되는 것을 알 수 있습니다.
실행계획을 먼저 보면, Index Seek를 하고 있습니다. 이것은 인덱슬르 이용해서 조건에 해당하는
값을 찾아가고 있다는 행동입니다. Index Seek와 Index Scan이 있는 이 두가지가 틀리다는 것을
알아야 합니다. Index Scan은 인덱스의 Leaf Page(인덱스 키값과 해당 키값의 데이터의 주소가
저장된 페이지)를 모두 뒤지는 연산이고, Index Seek는 인덱스 트리(B Tree)를 검색해서 원하는
데이터를 바로 찾아내는 방법입니다.
B Tree 역시 나중에 다루도록 하겠습니다.
여기서는 Index Seek를 했고, 그 후 Bookmark Lookup이라는 연산을 수행했습니다.
Bookmark Lookup은 실제 데이터를 찾아가는 과정이라고 보시면 됩니다. 인덱스안에는 noInt컬럼에 대한
값밖에 없습니다. 그러므로 tmpText까지 포함한 실제 데이터를 보여주기 위해서 실제 데이터를
찾아가는 과정이죠.
이렇게 TBL_IDX에서 데이터를 찾아내는 과정이 진행되었습니다.
결과적으로 TBL_IDX에서는 3개의 페이지만을 읽었다는 것이 중요합니다.
해당 SQL의 성능은 곧 페이지의 IO와 많이 연관이 있기 때문입니다.
페이지 IO를 줄이기 위해 노력하는 것이 해당 SQL문에 대한 튜닝이 될 수 있습니다.
5. 인덱스를 사용하지 않는 경우에 대해서도 알아보도록 합시다.
SELECT *
FROM TBL_NO_IDX
ORDER BY noInt ASC
SELECT *
FROM TBL_IDX
ORDER BY noInt ASC
'TBL_NO_IDX' 테이블. 스캔 수 1, 논리적 읽기 수 1250, 물리적 읽기 수 0, 미리 읽기 수 0.
'TBL_IDX' 테이블. 스캔 수 1, 논리적 읽기 수 1113, 물리적 읽기 수 0, 미리 읽기 수 0.
Rows Executes StmtText
10000 1 SELECT * FROM [TBL_IDX] ORDER BY [noInt]
10000 1 |--Sort(ORDER BY:([TBL_IDX].[noInt] ASC))
10000 1 |--Table Scan(OBJECT:([PLANDB].[dbo].[TBL_IDX]))
go
위 두개의 SQL문은 정렬을 하고 있고, 모든 데이터를 보여주는 작업을 하고 있습니다.
TBL_NO_IDX는 특별히 설명할 것이 없고, TBL_IDX 테이블에 대한 SQL에 대해 말씀드리고 싶은 것은
인덱스가 있는데도, 인덱스를 사용하지 않았다는 것입니다. 이것은 SQL Server의 실행계획을 만들어
내는 옵티마이져란 녀석이 판단을 하기에, 인덱스를 사용하지 않는 것이 더 효율적이라
판단을 했기 때문입니다. 사실, 해당 SQL에서는 인덱스를 사용하게 할 수 있는 여건이 아무것도 없는
것이죠. 그러므로 TBL_IDX도 테이블을 스캔한 후에, Sort라는 작업을 하는 것을 볼 수 있습니다
우리는 테이블에 데이터를 집어넣을 때, 1부터 시작해서 데이터를 넣었습니다. 그러므로 실제 저장된데이터는 1부터
10000까지 시퀀스하게 저장되어 있습니다. 하지만, 관계형 DB는 순서가 없으므로
이런 순서는 언제가는 깨지게 됩니다. 그러므로, ORDER BY를 이용해서 꼭, 순서를 명시하는
SQL문이 필요한 것이죠.
6. 인덱스를 사용해서 Sort를 제거하기
--인덱스를 사용해서 Sort를 제거
SELECT *
FROM TBL_IDX (index = tbl_idx_idx1)
--어마어마한 논리적 읽기 수
'TBL_IDX' 테이블. 스캔 수 1, 논리적 읽기 수 10024, 물리적 읽기 수 0, 미리 읽기 수 0.
Rows Executes StmtText
10000 1 SELECT * FROM TBL_IDX (index = tbl_idx_idx1)
10000 1 |--Bookmark Lookup(BOOKMARK:([Bmk1000]), OBJECT:([PLANDB].[dbo].[TBL_IDX]))
10000 1 |--Index Scan(OBJECT:([PLANDB].[dbo].[TBL_IDX].[tbl_idx_idx1]))
힌트를 주어서 Order By를 제거 할 수 있습니다. 데이터는 무순서로 저장이 되지만,
인덱스는 인덱스로 지정한 컬럼에 대해 순서적으로 저장되어 있으므로 인덱스를 경유해 검색을
하게 된다면 Order By와 동일한 결과를 얻을 수도 있습니다.
하지만 위의 SQL의 IO를 보시면, 10024라는 어마어마한 물리적 읽기가 수행된 것을 알 수 있습니다.
그것은 위의 SQL이 모든 데이터를 대상으로 하므로 실제 데이터를 찾아가는 과정이 필요하기 때문입니다.
위의 실행계획은 이런식으로 실행이 됩니다.
첫번째 인덱스 컬럼에 위치->주소를 참조 실제 데이터를 가져온다.->다음 인덱스로 이동
두번째 인덱스 컬럼에 위치->주소를 참조 실제 데이터를 가져온다.->다음 인덱스로 이동
...
..
만건이 이렇게 수행되어지므로 만번의 Bookmark Lookup이 일어나게 되고, 이것에 대한
부하가 심한 것입니다. 만약에 클러스터드 인덱스를 사용한다면, 이런 Bookmark Lookup은 일어나지 않죠.
7. 커버된 인덱스의 사용
--커버된 인덱스를 사용해서 페이지IO를 줄일 수 있다.
SELECT noInt
FROM TBL_IDX (index = tbl_idx_idx1)
--커버된 인덱스는 확연한 성능개선
Rows Executes StmtText
10000 1 SELECT noInt FROM TBL_IDX (index = tbl_idx_idx1)
10000 1 |--Index Scan(OBJECT:([PLANDB].[dbo].[TBL_IDX].[tbl_idx_idx1]))
'TBL_IDX' 테이블. 스캔 수 1, 논리적 읽기 수 24, 물리적 읽기 수 0, 미리 읽기 수 0.
결과를 보면 인덱스 스캔만 있을 뿐, Bookmark Lookup이 없는 것을 알 수 있습니다.
이것은 SELECT절에 noInt만 표시되어 있기 때문입니다. noInt컬럼에 대한 정보는
인덱스에 이미 있으므로 실제 테이블을 뒤질 필요가 없는 것입니다.
이렇게 인덱스만으로 쿼리문이 해결되는 것을 인덱스로 커버된 쿼리라고 합닙다.
커버된 쿼리의 내용 역시 후에 자세히 따로 다루도록 하겠습니다.
하지만 이런 커버된 쿼리는 SQL에 있는 모든 컬럼들이 인덱스 안에 있어야 한다는 제약조건이
있다는 것을 유의해서 사용해야 합니다.
간단하게 인덱스와 실행계획에 대해 살펴보았습니다.
인덱스를 사용하는 쿼리는 Index Seek가 나타나게 되고, Index Seek가 나온다 해도 Bookmark Lookup이 많다면
곧, 성능에 부하가 생긴다는 것이죠. Bookmark Lookup은 인덱스로 찾고자 하는 데이터가 많을수록 많이
나타나게 됩니다.
그러므로 인덱스를 이용해서 데이터를 찾는 것은 많은 데이터가 아닌, 적은 데이터여야 합니다.
물론, 이 적다는 의미가 어느정도인지는 시스템에 따라, 상황에 따라 달라지게 됩니다.
아무리 적어도 1000건까지는 인덱스를 사용해도 괜찮다고 제 개인적으로 생각합니다.
(물론, 인덱스의 깊이에 따라 달라지겠지만요. 그외 클러스터드 인덱스도 고려요소가 됩니다.)
여기서 여러분들이 최소한 건져야 할 것은,
Index Scan이냐, Seek와, Bookmark Lookup이 무엇인지, 그리고 실행계획을 볼려면 어떤
옵션을 주어야 하는지 정도라 생각되어 집니다.
부족한 글 읽어주셔서 감사합니다.
설정
트랙백
댓글
글
설정
트랙백
댓글
글
이곳 Tip&Tech의 글 중에 게시판의 속도를 높이자.. 라는 글에서 사용한 방법이
바로이 파생 테이블이기도 합니다.
/*
-----------------------------------------------------------------------
소개
-----------------------------------------------------------------------
+ 파생 테이블이란?
우선, 파생 테이블에 대해서 간단히 소개를 하겠습니다.
파생 테이블(Derived Table, 인라인 뷰라고도 하죠)
T-SQL에서 FROM절에는 일반적으로 Table_Source 형식의 데이터 집합이 올
수 있죠.
다음은 테이블 소스 형식의 예입니다.
- Table
- View
- Rowset 함수
- OPENXML 함수
- Derived Table(파생 테이블)
위에서 보는 것처럼, 테이블 소스가 될 수 있는 형식은 다양합니다.
그러나, SQL을 전문적으로 배우기 전에는 FROM절 하면 항상 테이블 또는 뷰 정도만을
생각하게 됩니다.
이번엔 파생 테이블에 대한 기본적인 사용법과 함께, 어떤 경우에 파생 테이블을
적용할 수 있는지, 또한 다른 방법들과 어떤 차이가 있는지 다양한 상황을 통해
살펴 보도록 하겠습니다.
+ 집합 개념의 시작
이번 강좌를 진행하면서, 제 개인적인 목적은 Advanced T-SQL에 대한 내용을
전반적으로 살펴보면서 집합적 개념을 인식할 수 있도록 유도하는 것입니다.
이전 강좌를 통해서도 집합 개념에 대한 중요성을 계속 언급을 드리고 있습니다.
파생 테이블 역시, 제대로 사용하기 위해서 그리고 그 이점을 최대한 활용하기 위해선
집합적 개념의 이해와 접급 시도를 필요로 합니다.
특히 두 개 이상의 테이블을 조인하거나, 다른 집합에서 파생된 데이터를 가공하거나
다른 집합을 기준으로 새로운 집합을 산출하는 처리를 하는 경우 파생 테이블의 사용
여부는 상당한 차이를 보여줍니다.
여러분들은, 집합 개념의 이해가 어떤 내용인지를 이 강좌의 마지막 예제를 통해서
느끼실 수가 있으실 겁니다.
+ 서브 쿼리, 임시 테이블의 대체
파생 테이블을 적용할 수 있는 또 다른 사례가 바로 서브 쿼리나 임시 테이블을
사용하는 쿼리입니다.
SQL의 정답은 없다라는 말을 곧 잘 합니다. 하나의 결과를 산출하기 위해서 시도할
수 있는 방법은 여러가지가 있으며, 하나의 방법이 좋은 결과를 보였다고 해서 다른
SQL에서도 동일하다는 보장은 없다는 뜻 입니다.
서브 쿼리, 임시 테이블(또는 2000의 Table 데이터형) 그리고 파생 테이블 이러한
방법 중 가장 좋은 결과(성능 및 비용 측면)를 가지는 방법을 선택하는 시도가
필요합니다.
-----------------------------------------------------------------------
준비 사항
-----------------------------------------------------------------------
자, 그럼 강좌를 보기 전에 기본적인 준비가 있어야 겠죠.
쿼리 분석기에서 윈도우를 하나 오픈하시죠(Ctrl-N),
그리고 엔터프라이즈 관리자에서 Northwind 데이터베이스 다이어그램을 하나
작성하시면 좋겠습니다.
제공되는 예제는 기본적으로 Northwind DB를 사용할 것입니다.
-----------------------------------------------------------------------
파생 테이블의 미리보기 예제
-----------------------------------------------------------------------
우선, 간단한 예제를 먼저 보도록 하겠습니다.
*/
USE Northwind
GO
SELECT p.productid, p.quantity
FROM (SELECT productid, sum(quantity) quantity
FROM dbo.[order details] od
GROUP BY productid) as p
/*
-----------------------------------------------------------------------
파생 테이블 작성 규칙
-----------------------------------------------------------------------
1. ANSI-92 SQL 표준.
2. ()안에 SELECT문을 기술.
3. 반드시 테이블 별칭(Alias)을 기술합니다.
-- 테이블 별칭을 생략한 경우
SELECT p.productid, p.quantity
FROM (SELECT productid, sum(quantity) quantity
FROM dbo.[order details] od
GROUP BY productid)
서버: 메시지 170, 수준 15, 상태 1, 줄 4
줄 4: ')' 근처의 구문이 잘못되었습니다.
파생 테이블의 ANSI-92 표준이기 때문에 다른 DBMS에서도 동일하게 적용하실 수 있는
기능입니다. SQL Server는 6.5버전부터 지원이 됩니다.
작성 방법은 어렵지 않을 것입니다.
쉽게 생각하셔서, SELECT문과 별칭을 가진 테이블 소스라고 생각하시면 되죠.
기본적인 사항을 배우셨으니, 이제 실제 다양한 사례를 통해서 파생 테이블을 어떤
경우에 적용할 수 있는지 보도록 하겠습니다.
*/
/*
-----------------------------------------------------------------------
파생 테이블 적용 사례
-----------------------------------------------------------------------
1. 파생 테이블과 조인하기
예제. Products 테이블에서 제품별 단가를 산출하되,
같은 종류 별(categoryid) 평균단가(avgprice) 를 함께 출력한다.
참조테이블.
Products
출력양식.
productid unitprice avgprice
----------- --------------------- ---------------------
1 18.0000 42.3708
2 19.0000 42.3708
3 10.0000 23.0625
...
*/
USE northwind
-- 각 제품의 단가 출력
SELECT p.productid, p.unitprice
FROM dbo.products as p
-- 같은 종류별로 평균 단가 출력
SELECT avg(unitprice) as avgprice
FROM dbo.products
GROUP BY categoryid
-- 1) 서브 쿼리를 이용한 최종 결과
SELECT p.productid, p.unitprice,
(SELECT avg(unitprice)
FROM dbo.products a
WHERE a.categoryid = p.categoryid
GROUP BY a.categoryid) as avgprice
FROM dbo.products as p
-- 2) 파생 테이블을 이용한 최종 결롸
SELECT p.productid, p.unitprice, a.avgprice
FROM dbo.products p JOIN
(SELECT categoryid, avg(unitprice) as avgprice
FROM dbo.products
GROUP BY categoryid) AS a ON a.categoryid = p.categoryid
ORDER BY p.productid
/*
2. (GROUP BY 절과 함께 UPDATE하기)
예제. 매출액( sum(unitprice) ) 5위 까지의 제품의 단가를 20% 상향 조정
하기 위한 update 작성.
임시 테이블을 작성할까?
참조테이블.
[Order Details]
출력양식.
없음.
*/
-- 매출액 5위까지 산출
SELECT TOP 5 productid, sum(unitprice) as unitprice
FROM dbo.[order details]
GROUP BY productid
ORDER BY unitprice DESC
-- 매출액 1위인 38번 제품의 현재 단가: 263.5 (확인용)
-- (여러분들의 금액을 적어두시면 됩니다)
SELECT productid, unitprice
FROM dbo.products
WHERE productid = 38
-- 파생 테이블을 이용한 경우, 316.2로 변경(38번 제품)
UPDATE p SET p.unitprice = p.unitprice * 1.2
FROM dbo.products as p JOIN
(SELECT TOP 5 productid, sum(unitprice) as unitprice
FROM dbo.[order details]
GROUP BY productid
ORDER BY unitprice DESC) as a
ON a.productid = p.productid
/*
3. 재미있는 예제.
(통계치에 대한 분포 데이터 출력)
예제. 고객별 주문횟수에 대한 분포 데이터 출력
*/
SELECT customerid, count(*) as ordercnt
FROM dbo.orders
GROUP BY customerid
ORDER BY ordercnt
-- 파생 테이블을 이용한 경우, 재미있죠?
SELECT cnt, Replicate('=', count(*)) as freq
FROM (SELECT customerid, count(*) as cnt
FROM dbo.orders
GROUP BY customerid) as c
GROUP BY cnt
/*
문제 유형.
1:M관계의 조인후 1 관계 산출하는 SQL
파생 테이블을 적용해서 성능 향상을 유도할 수 있는 일반적인 사례가 바로
GROUP BY 절이 사용되는 경우입니다.
GROUP BY 절은 M쪽 관계의 집합을 1쪽 관계로 산출하는 집합 연산입니다.
특히 조인과 함께 적용되는 경우 JOIN과 GROUUP BY 이 두가지 집합 연산의 처리
순서는 성능에 있어서 중요한 요소가 됩니다.
제 말의 의미를 아시겠는지?
아래 예제를 살펴보시고, 실제 성능 평가는 마지막에서 언급합니다.
요구하는 출력양식을 위한 SQL을 직접 작성해 보십시오.
그리고 파생 테이블을 사용한 경우와 비교를 해 보시기 바랍니다.
참조테이블.
Orders, [Order Details], Products
출력사항.
1996-12-31 이전에 주문된 제품별 단가의 합계 출력
출력양식.
-------------------------------
제품명 단가합계
-------------------------------
Alice Mutton 249.6000
Aniseed Syrup 8.0000
...
SQL 구현 방법
1. 일반 조인을 이용한 경우
2. 파생 테이블을 이용한 경우
*/
-- 1. 조인을 이용한 경우
-- 대부분의 개발자들이 이렇게 처리를 하십시다.
SELECT productname, sum(od.unitprice) sumprice
FROM dbo.[order details] od join dbo.orders o
ON o.orderid = od.orderid join dbo.products p
ON od.productid = p.productid
WHERE orderdate < '19961231'
GROUP BY productname
-- 2. 파생 테이블을 이용한 경우, 비교를 해 보시죠.
SELECT productname, sumprice
FROM dbo.products p
JOIN (SELECT productid, sum(od.unitprice) sumprice
FROM dbo.[order details] od join dbo.orders o
ON od.orderid = o.orderid
WHERE orderdate < '19961231'
GROUP BY productid) od
ON od.productid = p.productid
ORDER BY productname
/*
성능 비교
아래 세션 옵션(STATISTICS IO)을 ON으로 설정하신 뒤에 위의
두 명령을 쿼리 분석기에서 다시 실행하고 나면 아래와 같은 결과를 추가적으로
보여줍니다.
만일, 쿼리 분석기에서 실행 계획을 보고 평가하실 수 있는 분이라면 실행
계획도 함께 확인하시면 훨씬 도움이 되실겁니다.(Ctrl-K)
이 옵션을 ON으로 설정한 뒤, SQL을 실행하시면 쿼리 분석기의 결과 창에
실행 SQL에 의해 발생된 각 테이블의 페이지(데이터 페이지&인덱스 페잊) IO 횟수,
테이블 스캔 횟수 및 기타 정보를 보실 수가 있습니다.
SQL 성능 측정을 위한 기본적인 방법입니다.
자, 그럼 비교를 해 보시죠.
*/
SET STATISTICS IO ON
-- 1. 조인을 이용한 SQL을 실행한 경우의, 디스크 처리 통계 정보
-- 'Products' 테이블. 스캔 수 401, 논리적 읽기 수 802, 물리적 읽기 수 0, 미리 읽
기 수 0.
-- 'Order Details' 테이블. 스캔 수 151, 논리적 읽기 수 303, 물리적 읽기 수 0, 미
리 읽기 수 0.
-- 'Orders' 테이블. 스캔 수 1, 논리적 읽기 수 2, 물리적 읽기 수 0, 미리 읽기 수 0.
-- 2. 파생 테이블을 이용한 SQL을 실행 한 경우의, 디스크 처리 통계 정보
-- 'Products' 테이블. 스캔 수 74, 논리적 읽기 수 148, 물리적 읽기 수 0, 미리 읽기
수 0.
-- 'Order Details' 테이블. 스캔 수 151, 논리적 읽기 수 303, 물리적 읽기 수 0, 미
리 읽기 수 0.
-- 'Orders' 테이블. 스캔 수 1, 논리적 읽기 수 2, 물리적 읽기 수 0, 미리 읽기 수 0.
/*
2가지 IO 비교에서
'Products' 테이블에 대한 논리적 읽기 수를 비교해 보십시오.
1. 스캔 수:401, 논리적 읽기 수:802
2. 스캔 수:74, 논리적 읽기 수:148
상당한 차이의 Page IO를 보실 수가 있습니다.
예제에서 사용된 테이블의 레코드 수는 각각 Products(77), Orders(830),
Order Details(2155) 건 밖에 되지 않습니다.
대량의 데이터를 가진 테이블의 경우를 상상해 보십시오.
-----------------------------------------------------------------------
Horizontal Partitioning(=Partitioned View)
-----------------------------------------------------------------------
SQL Server 2000에 새로 추가된 Enterprise 기능 중에 한 가지가 바로
Distributed Partitioned View(분산 분할 뷰) 기능입니다.
데이터 베이스 층에서 데이터 로드 밸런싱을 통한 확장성을 구현할 수 있는
기능입니다.
이 분할 뷰를 파생 테이블을 형식으로도 구성을 하실 수가 있습니다.
분산 분할 뷰에 대해서는 기회가 닿는 대로 소개를 하도록 하겠습니다.
-----------------------------------------------------------------------
Inline Table-value 함수도 동일한 기능을 수행
-----------------------------------------------------------------------
SQL Server 2000에서 또 다른 추가 기능이 바로 UDF(사용자 정의 함수) 기능이죠.
UDF는 세 가지 형식으로 작성하실 수가 있습니다.
1. Scalar 함수
2. Table-value 함수 중
2-1) Inline
2-2) Multi Statement
입니다.
이 중 Inline Table-value 형식의 함수는
일반적인 뷰, 파생테이블과 동일하게 처리 방법으로 사용이 됩니다.
-----------------------------------------------------------------------
마무리.
-----------------------------------------------------------------------
파생 테이블에 대한 사례는 많이 있습니다.
너무 부담을 드릴 수는 없는 관계로 몇 가지 사례만을 소개 했습니다.
집합 개념의 대한 정립. 파생 테이블 활용에서부터 시작하십시오.
변환된 모습을 느끼실 수 있으실 겁니다.
이번 강좌도 여러분들에게 많은 도움이 되셨으면 하는 바램을 가져 봅니다.
벌써 새벽 4시군요, 오늘은 토요일, 즐거운 주말 되십시오.
설정
트랙백
댓글
글
<<봉봉 주세요 님 글을 가져왔습니다.>>
스 구축할 때 안정적으로 서비스하려면 한 서버에 톰캣을 4개 정도 구동시켜야 한다고 하던데 ㅎㅎ
http://www.ibm.com/developerworks/kr/li ··· 61017%2F
웹 개발자에게 있어 톰캣은 JSP를 배우거나 간단한 테스트를 하는 정도의 웹 컨테이너로 생각하는 경우가 많다. 하지만 근래 들어 기업 및 대형 포탈에서 상용 서비스를 위한 웹 컨테이너로서 톰캣을 선택해, 성공적으로 적용한 사례들이 늘고 있다. 톰캣에서 안정적인 웹 서비스를 제공하기 위해서 지원하는 기능은 5가지가 있다. 아파치 웹서버와 연동, 로드밸런싱, 세션 클러스터링, 데이터베이스 처리, 모니터링 및 관리 등이 그것이다.
이 문서에서는 로드밸런싱과 세션 클러스터링 위주로 설명을 할 것이며, 다음에 기회가 된다면 다른 부분에 대해서도 자세히 알아보도록 하겠다.
아파치 웹 서버와 톰캣의 연동
일반적으로 정적인 페이지를 서비스할 때는 웹서버가 훨씬 더 좋은 성능을 발휘한다. 또한 이렇게 역할 분담을 함으로 톰캣에 가중되는 부하를 줄여주는 효과도 얻을 수 있다. 아파치웹서버와 톰캣을 연동하는 것을 일반적으로 ‘커넥터(Connector)'라고 부르며, 여기에는 WARP 커넥터, JK 커넥터 그리고 JK2 커넥터가 있다. 이중에서 WARP와 JK2는 공식 커넥터에서 제외되었고 현재 남아 있는 것은 JK 커넥터뿐이다. 그럼 먼저 JK 커넥터를 이용해서 아파치 웹서버와 톰캣을 연동해 보도록 하겠다.
아파치 웹사이트에서 바이너리 혹은 소스 코드를 다운로드 받도록 하자. 유닉스 혹은 리눅스는 mod_jk.so이며 윈도우용은 mod_jk.dll이다. 이 파일을 아파치 웹서버의 modules 디렉토리에 저장한다(주의, 아파치 웹서버를 컴파일해서 사용하는 경우는 컴파일시에 DSO 기능이 가능하도록 설정해줘야 한다). 저장을 한 후에 아파치 웹서버에 해당 모듈을 인식시켜야 하며 아파치 웹서버의 httpd.conf 파일에 다음 내용을 추가하도록 하자.
리스트 1. httpd.conf
... LoadModule jk_module modules/mod_jk.so # 모듈 추가 JkWorkersFile "conf/workers.properties" # JK 설정 파일 위치 및 이름 JkLogFile "logs/mod_jk.log" # JK에 대한 로그 파일 위치 JkLogLevel info # 로그 레벨 지정 JkLogStampFormat "[%a %b %d %H:%M:%S %Y]" # 로그 시간 포맷 지정 JkRequestLogFormat "%w %V %T" # 로그 내용 포맷 JkMount /* loadbalancer # URL 링크 -> 모든 요청을 톰캣으로 지정 JkMount /servlet/* loadbalancer # URL 링크 -> servlet 요청을 톰캣으로 지정 ... |
위와 같은 설정을 하게 되면 아파치 웹서버로 들어온 모든 요청을 톰캣으로 재전송 하게 된다. 만일 JSP와 서블릿만 톰캣에서 서비스를 하고 나머지는 아파치 웹서버에서 서비스 하고자 한다면 다음과 같이 수정하면 된다.
JkMount /*.jsp loadbalancer # URL 링크 -> *.jsp 요청을 톰캣으로 지정 JkMount /servlet/* loadbalancer # URL 링크 -> servlet 요청을 톰캣으로 지정 |
httpd.conf에는 위의 내용이 전부이다. 그럼 이제 workers.properties 파일을 작성해 보도록 하겠다. 이 파일이 실제 로드밸런싱을 위한 설정이 되겠다.
|
라운드 로빈 방식의 로드밸런싱 설정
톰캣에서 제공하는 로드밸런싱은 정확히 톰캣 자체에서 제공하는 것이 아니라 아파치 웹서버와 연동되는 커넥터에 의해서 제공된다(로드밸런싱은 JK, JK2 커넥터에서만 제공된다). 현재는 라운드 로빈(Round Robin) 방식만이 제공되며 로드밸런싱에 대한 설정은 workers.properties 파일에서 정의하게 된다.
리스트 2. workers.properties
worker.list=tomcat1, tomcat2, loadbalancer worker.tomcat1.type=ajp13 worker.tomcat1.host=localhost worker.tomcat1.port=11009 worker.tomcat1.lbfactor=100 worker.tomcat2.type=ajp13 worker.tomcat2.host=localhost worker.tomcat2.port=12009 worker.tomcat2.lbfactor=200 worker.loadbalancer.type=lb worker.loadbalancer.balanced_workers=tomcat1,tomcat2 |
worker라는 개념은 톰캣의 프로세스로 보면 된다. 즉 worker를 설정하는 구성 요소는 JK 커넥터를 연결하는 방식(JK는 ajp13을 이용한다), 톰캣이 실행되어 있는 IP 혹은 도메인, ajp13 서비스 포트, 그리고 작업 할당량이다. 여기서 주의 깊게 볼 것이 작업 할당량인데 로드밸런싱 시에 lbfactor라는 작업량의 비율을 보고 라운드 로빈 방식의 서비스를 제공하게 된다. 여기서는 tomcat1과 tomcat2를 1대 2의 비율로 작업량을 할당한 것이다.
그럼 이제 남은 작업은 2개의 톰캣 프로세스를 실행시키는 것이다. 톰캣 프로세스를 여러 개 띄우는 방법은 2가지가 있다.
- 톰캣을 2개 설치해서 기동시킨다. 이때 포트 충돌을 피하기 위해 서버 포트, AJP13과 HTTP 1.1 커넥터 포트 2개를 충돌되지 않게 재정의 한다.
- 하나의 톰캣에 2개의 서비스를 정의하고 톰캣을 기동시킨다. 이때 AJP13과 HTTP1.1 커텍터 포트 2개를 충돌되지 않게 재정의 한다.
먼저 2개의 바이너리를 설치했다고 가정하면 각각의 톰캣은 다음과 같은 형태의 server.xml 파일로 적용해 준다.
리스트 3. server.xml
리스트 4. server.xml
리스트 5. server.xml
리스트 5는 하나의 톰캣 바이너리를 통해 2개의 프로세스를 실행시키는 것이다. 이렇게 하면 환경 설정의 편리성을 가져올 수 있지만 특정 서비스만 실행하거나 종료 시키는 것은 아직 지원되지 않는다. 즉 모든 서비스가 동시에 실행되거나 혹은 동시에 종료되는 것을 의미한다. 이런 점을 잘 판단해서 두 가지 형태의 환경 설정 중 하나를 선택하면 되겠다.
지금까지는 로드밸런싱에 대해 알아보았다. 위의 환경설정을 가지고 테스트를 하다 보면 한가지 문제가 발생한다. 예를 들어 어떤 사용자가 tomcat1을 이용해서 쇼핑몰 서비스를 받고 있다가 tomcat1이 비정상 종료를 하게 되었다. 이때 사용자가 웹 페이지를 요청하게 되면 아파치 웹서버는 tomcat1이 종료된 것을 인지하고 그 이후부터 서비스를 tomcat2로 요청하게 된다. 하지만 tomcat1에 저장되어 있던 쇼핑바구니 정보 즉 세션 정보는 사라진 상태다. 즉, 서비스는 유지되지만 사용자는 다시 이유도 모르게 처음부터 쇼핑 항목들을 등록해야 하는 문제를 가지게 된다. 이제부터는 이런 문제를 해결할 수 있는 톰캣 프로세스 간의 세션 정보 공유에 대해서 알아보겠다.
|
세션 클러스터링 설정
클러스터링은 톰캣 5.x 버전부터 지원이 되고 있지만 아직은 초기 단계이고 세션 클러스터링만이 제공되고 있는 수준이다. 기능이 많이 부족하긴 하지만 로드밸런싱과 더불어 사용할 경우에는 좀 더 안정적인 서비스를 제공할 수 있다. 작업을 해주어야 할 것은 다음과 같다.
server.xml에 <Cluster> 태그 정의 웹 어플리케이션의 web.xml에 <distributable/> 태그 추가
리스트 6. server.xml
|
웹 어플리케이션 작성을 통한 테스트
먼저 테스트를 위해서 간단한 웹 어플리케이션을 작성하도록 하겠다. 여기서 웹 어플리케이션 이름은 lbtest라고 하겠다.
리스트 7. index.jsp

그림 1. 테스트 결과 화면
이상으로 톰캣을 이용한 로드밸런싱과 세션 클러스터링에 대해서 알아보았다. 일반적으로 로드밸런싱과 클러스터링은 성능 향상이라는 측면과 안정성 확보에 그 목적을 가지고 있다. 물론 고가의 상용 웹 어플리케이션 서버에 비하면 많이 부족하고 하드웨어를 이용한 로드밸런싱과 클러스터링에 비하면 안정성이 떨어질 수도 있지만 저렴한 비용으로 최대의 안정성과 성능을 얻고자 한다면 한번쯤 시도해 볼만한 좋은 기능이라고 할 수 있다. 아무쪼록 리눅스, 아파치, 톰캣 그리고 오픈소스를 통해 즐거운 웹 어플리케이션 개발 환경을 느껴보기 바란다.
설정
트랙백
댓글
글
0. 윈도우의 네트워크 설정에서 '로컬 영역 연결'의 '등록정보'에서 '공유'탭을 선택하시고, '이 연결에 인터넷 연결 공유 사용'을 체크합니다...('로컬 네트워크의 경우' 항목에 'VMware Network Adapter VMnet8'을 선택해 놓습니다...)
1. 'VMware Network Adapter VMnet8'의 '등록정보'에서 '인터넷 프로토콜(TCP/IP) 등록 정보'의 IP주소와 서브넷마스크를 확인해 놓습니다...(대체로 IP는 192.168.0.1, 서브넷마스크는 255.255.255.0으로 잡혀 있을 것입니다...)
2. GuestOS 환경을 설정할때, NIC를 custom으로 잡으시고, vmnet8(NAT)을 선택합니다...()
3. Redhat Linux 9를 설치하시고 eth0의 설정을 IP는 VMWare의 'Edit -> Virtual Network Settings...'에서 'DHCP' 탭의 'VMnet8'의 'Properties'에 설정된 'Start IP Address'와 'End IP Address'의 범위 내에서 임의로 잡으시고, 서브넷마스크는 255.255.255.0, 게이트웨이는 VMWare의 'Edit -> Virtual Network Settings...'에서 'NAT'탭의 'Gateway IP address'를 확인하여 똑같이 넣습니다... 그리고 DNS는 1번 항목에서 확인하신 IP 주소를 입력하시구요... 이렇게 하면 설정이 모두 끝납니다...(종전의 가물거리는 기억으로 썼던 내용으로 인해 삽질하신 분들께 고개를 조아려 사죄드립니다...)
4. eth0 설정후 저장 하시고 다시 활성화 해준 후 ping으로 네트워크가 작동하는지 확인합니다...
이상이 제가 나름대로 정리한 내용이구요... vmnet 설정을 다른걸 잡아주거나 기존의 설정을 지우는 등의 조치가 다른 GuestOS를 사용하는데 문제를 야기하는듯 싶어서 기본 설정만으로 해결할 방법을 고심하던 끝에 성공한 방법입니다... 이렇게 하고나니 네트웍이 됐다가 안됐다가 하는 문제는 해결이 되더군요... 참고로 한컴 리눅스를 다른 GuestOS로 사용하실 경우 기존의 방식대로 NAT로 잡고 DHCP로 설정해서 사용하시면, 전혀 문제 없이 네트워크 작동됩니다... 그럼... ^^"""
설정
트랙백
댓글
글
객체들을 조작하기 위한 자료구조로 자바는 배열이나 Collection Framework 내의 여러클래스를 제공하고 있습니다.
Collection Framework는 크게 3가지 형태로 분류할 수 있는데 간단하게 살펴 보자면
- Map : key와 Value를 가지는 자료구조입니다. HashMap, Hashtable, TreeMap과 같은 클래스들을 자주 쓰죠.
- List : 순서가 있고 중복이 허용되는 자료구조입니다. ArrayList, LinkedList, Vector...
- Set : 중복을 허용하지 않습니다. HashSet, TreeSet...
이러한 자료구조 내에서 객체들을 컨트롤 할 때 정렬은 피할 수 없는 숙명이죠.
1. 정렬해야 하는데 정렬 알고리즘을 모르겠다. 누가 정렬 좀 안해주나?
버블소트는 간단하지만 퍼포먼스에 문제가 있고
일반적으로 가장 빠른 퀵소트는 구현하기가 까다롭습니다.
버블소트조차도 귀찮으신 분들을 위해 친절하게도 자바는 여러분에게 고성능(?)의 정렬기능을 제공하고 있습니다.
그러나 우리는 자바가 제공하는 정렬기능을 사용하기 위해서 한두가지는 해야 합니다. 공짜는 없는거죠.
먼저 정렬을 위한 두가지 인터페이스에 친숙해질 필요가 있습니다.
java.lang.Comparable
java.util.Comparator
두 인터페이스가 서로 다른 패키지에 속해 있다는 사실에 유의하시구요.
Comparable 인터페이스는 객체의 고유한 순서를 제공하기 위한 것이라고 보면 되는데요.
우리말로 '비교할 수 있는' 정도로 풀 수 있겠죠.
그 뜻대로 이 인터페이스를 구현한 클래스의 객체들은 배열이나 컬렉션 프레임웤에서
자신과 딴넘을 비교할 수 있기 때문에 정렬의 기본조건을 충족시키고 있습니다.
정렬의 기본조건(객체간의 대소비교, 선후비교)이 준비되어 있기 때문에 정렬은 java API에 맡기면 되는 겁니다.
아래의 소스에서 우리는 Customer 클래스를 만들고 Comparable 인터페이스를 구현했습니다.
Comparable 인터페이스를 구현했기 때문에 그 인터페이스에서 정의한 compareTo 메쏘드를 반드시 오버라이딩 해야하죠.
이 메쏘드가 바로 자신과 딴넘을 비교해서
자기자신이 딴넘보다 앞에 와야하면 -1을, 똑같으면 0을, 뒤에 와야하면 1을 리턴하게 됩니다.
Customer 클래스에서는 디폴트로 한글이름으로 정렬되도록 compareTo를 재정의 했습니다.
이렇게만 구현을 해 놓으면 Customer로 이루어진 배열이 있다면
Arrays.sort(arr);
Customer로 이루어진 리스트(컬렉션프레임웤)가 있다면
Collections.sort(list);
를 호출하기만 하면 군말 없이 정렬해 줍니다.
자바API에서도 여러 클래스들이 이 Comparable을 구현하고 있는데요.
API문서를 참고하면
BigDecimal, BigInteger, Byte, ByteBuffer, Character, CharBuffer, Charset, CollationKey, Date, Double, DoubleBuffer, File, Float, FloatBuffer, IntBuffer, Integer, Long, LongBuffer, ObjectStreamField, Short, ShortBuffer, String, URI
등의 클래스들이 있습니다.
이러한 클래스들의 자료를 다룰때는 위의 sort 메쏘드를 자연스럽게 불러주면 되겠죠?
자바가 내부적으로 어떻게 정렬을 수행하는지 궁금하지 않으십니까?
그러면 SDK 설치 디렉토리 밑에 src.zip파일을 찾아 java.util.Arrays와 java.util.Collections의소스를 뜯어보십시오.
Collections의 sort(List)는 아규먼트로 들어온 list를 배열로 변환해서 다시 Arrays.sort(array)를 호출하며 Arrays.sort(array)는 합병정렬을 하고 있습니다
아마 합병정렬은 정렬성능도 우수하지만 정렬시간이 거의 일정하기 때문에 사용하는 것 같습니다.
(퀵소트는 최악의 경우 O(n^2) 의 시간이 걸릴수도 있습니다.)
단 메모리를 자기자신만큼, 그리고 절반씩 쪼개지는 크기들 만큼씩 더 사용한다는게 단점이죠.
우리는 Customer 클래스들이 배열로 되어 있건 리스트에 들어있건 한글이름으로는 정렬할 수는 있는데 그렇다면 나이순이라든지 영문이름순으로, 즉 다른 기준으로 정렬하고 싶을 땐 어떻게 할까요?
이럴때를 위해서 만들어 놓은 인터페이스가 Comparator입니다.
우리말로 '비교기', '비교측정기' 정도로 번역할 수 있는데 두 객체의 대소와 선후를 구현의도의 기준에 따라 판별해 줍니다.
이 인터페이스를 구현하는 클래스도 마찬가지로 compare 메쏘드를 구현해야 하는데요.
아규먼트로 들어오는 두개의 Object를 비교해서 역시 compareTo 와 같은 방식으로 리턴합니다.
그리고 아래처럼 사용하면 배열이나 리스트를 Comparator의 기준에 따라 정렬을 수행하게 됩니다.
Arrays.sort(arr, new YoungOrderComparator());
Collections.sort(list, new EngNameComparator());
2. sort()를 부르기도 귀찮다. 그냥 알아서 줄 좀 서 봐라.
자바는 친절하게도 위의 요구까지 들어주고 있는데
TreeMap이나, TreeSet이 그 기대에 부응하는 클래스들입니다. (Tree~가 붙어 있죠? ^^)
TreeMap은 key로 정렬을 하게 되고 TreeSet은 그 원소들을 정렬합니다.
위의 컨테이너 객체에 원소들을 넣는 족족 알아서 정렬됩니다. 코딩할 일이 없습니다.
리스트 같은 객체들을 인자로 받아서 TreeSet을 만들면 알아서 기본순서로(compareTo에 정의된 대로) 정렬됩니다.
Set set = new TreeSet(list);
정렬기준을 바꾸고 싶다면 Comparator를 구현한 객체를 생성자로 만든후 리스트를 집어넣어 줍니다.
Set set2 = new TreeSet(new YoungOrderComparator());
set2.addAll(list);
아래의 소스에 위에 언급한 사항을 간단하게 구현해 보았습니다.
자바의 컬렉션 프레임웤, 정렬기능 등을 차근차근 살펴보면 Interface, 다형성 등의 묘미를 만끽할 수 있죠.
이러한 객체지향적 언어로서의 매력은 이곳외에도 자바API의 여러부분에서 표현되어져 있습니다.
JAVA는 정말 아름다운 언어임에는 틀림없습니다.
import java.util.*;
public class A {
public static void main(String args[]) {
// 다섯명의 고객에 대한 배열 생성
Customer[] arr = new Customer[] {
new Customer("헤더 로클리어",1961, "Heather Deen Locklear"),
new Customer("데미 무어", 1962, "Demetria Gene Guynes"),
new Customer("안젤라 바셋", 1958, "Angela Bassett"),
new Customer("신디 크로퍼드", 1966, "Cintia Ann Crawford"),
new Customer("캐서린 제타 존스", 1969, "Catherine Jones")
};
printArray(arr, "Before Array sort Using Default sort");
// 배열을 정렬 (클래스에 정의된 기본정렬)
Arrays.sort(arr);
printArray(arr, "\nAfter Array sort Using Default sort");
// 배열을 어린 나이부터 정렬
Arrays.sort(arr, new YoungOrderComparator());
printArray(arr, "\nAfter Array sort Using YoungOrderComparator");
List list = Arrays.asList(arr); // 배열을 리스트로
Collections.shuffle(list); // 리스트의 순서를 마구 섞어 주세요.
printList(list, "\nBefore List sort Using Default sort");
// 리스트를 정렬 (클래스에 정의된 기본정렬)
Collections.sort(list);
printList(list, "\nAfter List sort Using Default sort");
// 리스트를 영문이름으로 정렬
Collections.sort(list, new EngNameComparator());
printList(list, "\nAfter List sort Using EngNameComparator");
// 디폴트 정렬할 수 있는 TreeSet을 만든다
Set set = new TreeSet(list);
System.out.println("\nAfter Making Set Using Default sort\n" + set);
// 어린 나이부터 정렬할 수 있는 TreeSet을 만든다
Set set2 = new TreeSet(new YoungOrderComparator());
set2.addAll(list);
System.out.println("\nAfter Making Set Using YoungOrderComparator\n" + set2);
}
static void printArray(Customer[] a , String title) {
System.out.println(title);
for (int i=0; i<a.length; i++)
System.out.println(a[i]);
}
static void printList(List l, String title) {
System.out.println(title);
for (int i=0; i<l.size(); i++)
System.out.println(l.get(i));
}
}
// 디폴트 소팅을 위해서 Comparable 인터페이스를 구현한다.
class Customer implements Comparable {
String name;
int birthYear;
String engName;
// Constructor
public Customer(String name, int birthYear, String engName) {
this.name = name;
this.birthYear = birthYear;
this.engName = engName;
}
// Object의 toString 메소드 overriding.. 객체의 문자적 표현
public String toString() {
return name + "(" + engName + ") " + birthYear + "년생";
}
// Comparable 인터페이스를 구현한 클래스에서 반드시 overriding 해야만 하는 비교 메쏘드
public int compareTo(Object o) {
// String의 compareTo 메소드를 호출(사전순서적( lexicographically)으로 비교)
return name.compareTo(((Customer)o).name);
}
}
// 젊은 순서대로 정렬하기 위해 Comparator 인터페이스를 구현
class YoungOrderComparator implements Comparator {
public int compare(Object o1, Object o2) {
int by1 = ((Customer)o1).birthYear;
int by2 = ((Customer)o2).birthYear;
return by1 > by2 ? -1 : (by1 == by2 ? 0 : 1); // descending 정렬.....
}
}
// 영문이름으로 정렬하기 위해 Comparator 인터페이스를 구현
class EngNameComparator implements Comparator {
public int compare(Object o1, Object o2) {
String en1 = ((Customer)o1).engName;
String en2 = ((Customer)o2).engName;
return en1.compareTo(en2); // ascending 정렬
}
}
 이올린에 북마크하기
이올린에 북마크하기트랙백 주소 :: http://yobaboom.tistory.com/trackback/17
-
Subject
설정
트랙백
댓글
글
| 수행할 작업... | ||
|
명령... : <<입력 | ||
| vi를 호출하여 file편집. | ||
|
vi file Enter | ||
| 커서 앞에 문자 삽입 | ||
|
i | ||
| 커서 뒤에 문자 추가 | ||
|
a | ||
| 문자 한 개 삭제 | ||
|
x | ||
| 명령 모드로 복귀 | ||
|
ESC | ||
| 커서를 오른쪽으로 이동 | ||
|
l 또는 오른쪽 화살표 키 | ||
| 커서를 왼쪽으로 이동 | ||
|
h 또는 왼쪽 화살표 키 | ||
| 커서를 위로 이동 | ||
|
k 또는 위 화살표 키 | ||
| 커서를 아래로 이동 | ||
|
j 또는 아래 화살표 키 | ||
| 변경 사항을 저장하지 않고 vi 종료 | ||
|
:q! Enter | ||
| 현재 파일을 기록(저장) | ||
|
:w | ||
| 현재 파일을 기록하고 vi(종료) | ||
|
:wq | ||
| 현재 파일을 filename에 기록 | ||
|
:w filename | ||
| 현재 파일을 filename에 겹쳐 쓰기 | ||
|
:w! filename | ||
| 현재 파일의 x줄에서 y줄까지를 filename에 기록. | ||
|
:x,y w filename(x,y는 특정 줄 번호이거나 위치 표시입니다.) | ||
| 현재 파일에 filename의 내용을 삽입 | ||
|
:r filename | ||
| vi를 수행하는 도중에 HP-UX 명령을 실행 | ||
|
:!command | ||
| 현재 파일을 인쇄 명령을 실행 ( 2장 “파일과 디렉토리 작업 ”, “파일 보기 및 인쇄 ”) | ||
|
:!lp % | ||
RECENT COMMENT